
안녕하세요.
과제를 진행하던 중 안양시게시판을 스크래핑(scraping) 후 워드클라우드(wordcloud)로 표현해볼 일이 있었습니다.
이와 관련해서 진행했던 것들에 대해 소개하고자 합니다.
윈도우 10 환경이며 사용언어는 python을 사용하였습니다.
스크래핑시에 주의할점은 웹 서버에 무리가 가지 않아야하고, 공개해도 상관 없는 데이터인지 확인하는 것 등등 이 있습니다.
웹 페이지 마다 코드 구조들이 달라서, 크롤링이나 스크래핑 하기 전에 웹페이지의 구조가 바뀌었는지 확인해야하는 번거로움이 따르지만
스크래핑으로 필요한 데이터를 수집하고, 워드클라우드로 키워드를 한번에 볼 수 있었습니다.
게시판에서 사용할 데이터 확인
먼저 안양시의 정책에 대한 게시물을들 중 '안녕, 안양'에서 정책 등 공공정보에 대한 게시물이 있는 것을 찾았습니다.
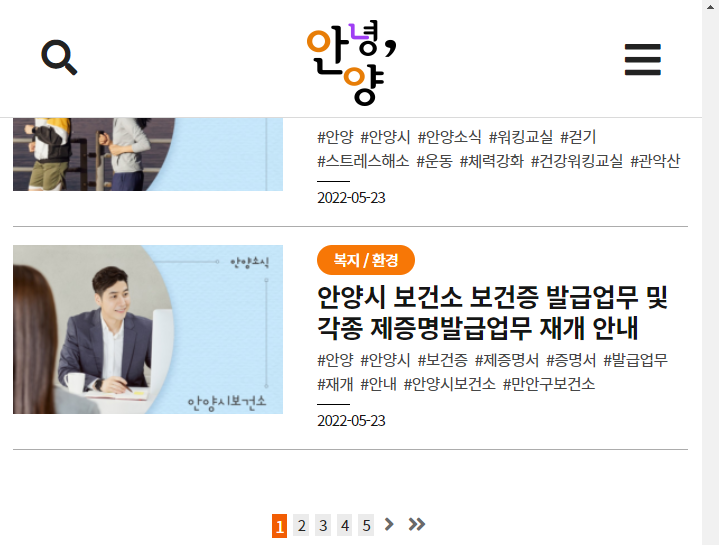
위의 이미지는 누구나 접근할 수 있는 안양시 홈페이지에서 공개한 홈페이지의 정책 등 공공정보에 대해 게시되어 있는 사이트의 게시판 입니다.
info
사용했던 브라우저는 크롬을 사용하였습니다.
게시물 중에서 필요한 것은
1. 2022 년도에 게시한 게시물
2. 게시물 제목
위 두가지입니다.
tip
크롬 브라우저에서 'ctrl + shift + c' 를 누르면 마우스 커서위치의 element를 확인할 수 있습니다.
안양시의 정책 등 공공정보에 대해 게시되어 있는 사이트의 게시판을 스크래핑 했습니다.
웹 스크래핑
스크래핑에서 request로 html 페이지를 가져오고
그 후에 파서를 통해서 파싱후에
필요한 데이터를 가져오는 순서로 진행하였습니다.
내재되어이urllib 라이브러리 request 로 HTML 페이지를 요청하고
저는 BeautifulSoup 라이브러리로 파싱 하고 '제목' 및 '게시 날짜'를 가져옵니다 .
from bs4 import BeautifulSoup
import urllib.request
while 1 :
next_page = url
# scraping
html = urllib.request.urlopen(next_page)
# parsing
soup = BeautifulSoup(html,'html.parser')
title = soup.select('div.sub-newslist-right > h2 > a > span.pc-content')
title_date = soup.select('div.sub-newslist-right > h5')
# data set 만들기
for text, date in zip(title, title_date):
contents.append([text.get_text(), date.get_text()])
# 다음 페이지에 대한 정보 가져오기
link = soup.find('a', class_='page-link', rel='next')
# 다음페이지가 없을경우 종료
if link is not None:
url = link.get('href')
else:
break;
가져온 데이터 중에서 필요한 년도만 가져옵니다.
# 년도만 가져오기
length = len(contents)
for i in range(length):
contents[i][DATE_INDEX] = contents[i][DATE_INDEX][:4]
text = ''
# target 년도 text 가져오기
for i in range(length):
if contents[i][DATE_INDEX] == target_year:
text = text + ' ' + contents[i][TEXT_INDEX]
게시판의 html을 확인해서 제목을 가져옵니다.
워드클라우드
가져온 제목을 워드 클라우드로 표현해 보겠습니다.
먼저 문장을 가져온 것이어서 형태소 분석을 통해서 명사만 가져와야합니다.
직접 구현하는 것 보단 구현이 잘 되어있는 라이브러리를 사용했습니다.
형태소 분석에는 잘알려진 koNLPy 라이브러리를 사용고, 여러 분석기들 중에서 Okt 분석기를 사용했습니다.
note
다른 분석기에 대한 재미있는 테스트는 'https://mr-doosun.tistory.com/22' 참고해보시길 바랍니다.
명사만 가져오고 단어개수가 1인것은 제외합니다.
명사만 가져온 후에 단어 개수 count dictionary를 구합니다.
from konlpy.tag import Okt
from collections import Counter
# 명사만 추출
okt = Okt()
nouns = okt.nouns(text)
# 단어의 길이가 1개인 것은 제외
words = [n for n in nouns if len(n) > 1]
# 위에서 얻은 words를 처리하여 단어별 빈도수 형태의 딕셔너리 데이터를 구함
words_dict = Counter(words)
간단하게 제외할 단어를 count dictionary 에서 지우겠습니다.
erase_word = ['안양', '안양시', '올해']
# 제외하고 싶은 단어 제거
for key in erase_word:
del words_dict[key]
워드 클라우를 생성할 딕셔너리 데이터들가지고 워드클라우드를 생성합니다.
from wordcloud import WordCloud
# 워드클라우드 옵션 설정 및 생성
wc = WordCloud(
font_path='malgun',
width=400,
height=400,
scale=2.0,
max_font_size=700,
contour_width=5,
contour_color='black',
background_color='white',
stopwords=stopwords
)
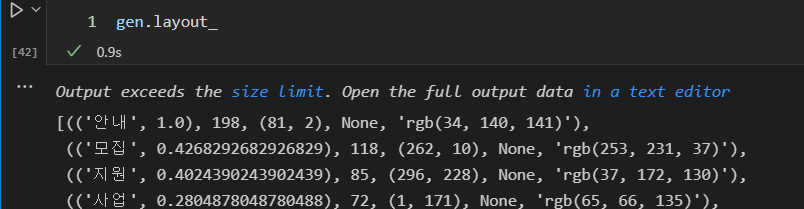
gen = wc.generate_from_frequencies(words_dict)
info
단어중 제가할 단어들을 선택하는 옵션인stopwords 가 있지만 generate_from_frequencies를 사용하면 해당 옵션을 무시합니다.
워드클라우드를 생성하면 해당 클래스가 반환됩니다.
레이아웃을 보면 각 단어마다 빈도수, 폰트크기, 위치, 회전 여부 색상 이런식으로 리스트의 형태로 되어있는 것을 알 수 있습니다.
워드 클라우드로 표현한것을 뿌리면
import matplotlib.pyplot as plt
plt.title('안 양 시', fontsize=42, fontweight="bold")
plt.axis('off')
plt.imshow(gen)
plt.show()

사각형모양으로 된 워드클라우드가 생성되었습니다.
안양시니까 안양시 모양으로 뿌려보겠습니다.
시군구 행정동 경계(센서스 시군구 경계를 사용했습니다.)에서 안양시부분을 떠옵니다.
안양시의 지도모양을 가져와서 마스크(mask)로 사용합니다.
옵션으로 설정해서 이미지를 뿌리면
import numpy as np
# 워드클라우드 그릴 mask 선택
img = Image.open('안양시.png')
wc_mask = np.array(img)
wc = WordCloud(
font_path='malgun',
width=400,
height=400,
scale=2.0,
max_font_size=700,
mask = wc_mask,
contour_width=5,
contour_color='black',
background_color='white',
)
gen = wc.generate_from_frequencies(words_dict)
plt.title('안 양 시', fontsize=42, fontweight="bold")
plt.axis('off')
plt.imshow(gen)
plt.show()

위와 같이 안양시 행정동 경계 모양으로 워드클라우드가 표현됩니다.
추가적으로 안내, 모집, 지원, 사업, 공고, 운영, 신청의 단어를 제외 해보았습니다.

안양시에서 '코로나', '방역', '도서관', '청년', '온라인', '교육' 등을 메인 키워드를 가지고 있는것을 확인할 수있습니다.